1. 외부 데이터 불러오기
2. R에 내장된 데이터
3. 기술통계
4. Box plot(상자도표, 상자그림)과 해석
5. Histogram(히스토그램)
1. 외부 데이터 불러오기
데이터 파일을 불러옵니다. txt 파일과 dat 파일은 read.table() 함수를, 엑셀을 이용한 csv 파일은 read.csv() 함수를 사용합니다. 이때 파일 경로는 \\(역슬래시 2번) 또는 /로 구분합니다.
read.table("파일 경로")
read.csv("파일 경로")
csv 파일을 불러와 dat이라는 변수에 저장합니다. 데이터 파일의 1행이 변수명인 경우 header=TRUE로 주면 1행을 열 이름으로, 2행부터 데이터의 1행으로 가져옵니다. 변수명이 없는 파일의 경우 header=F로 가져옵니다. 만약 데이터를 불러왔는데 한글이 깨지는 오류가 발생한다면 encoding="UTF-8"을 옵션으로 줍니다.
dat<-read.csv("C:\\Users\\주소\\파일명.csv", header=TRUE, encoding="UTF-8")
불러온 데이터를 확인합니다. 전체 데이터를 보려면 불러온 변수명(dat)을, 위에서 몇 줄만 보려면 head(dat, n= ), 아래에서 몇 줄만 보려면 tail(dat, n= )을 입력합니다. head()와 tail() 함수의 경우 n을 생략하면 기본으로 6줄을 보여줍니다.
> dat #전체 데이터 보기
> head(dat) #위에서부터 6줄 보기
> head(dat, n=2) #위에서부터 2줄 보기
> tail(dat) #아래서부터 6줄 보기
> tail(dat, n=2) #아래서부터 2줄 보기
2. R에 내장된 데이터
내장된 데이터를 불러오려면 data()함수를 쓰면 되는데, 외부 데이터와 마찬가지로 head(), tail() 함수 사용이 가능합니다. 패키지 설치가 필요한 경우 설치 후 불러옵니다.
> data(trees)
> head(trees)
Girth Height Volume
1 8.3 70 10.3
2 8.6 65 10.3
3 8.8 63 10.2
4 10.5 72 16.4
5 10.7 81 18.8
6 10.8 83 19.7불러온 데이터 또는 변수를 삭제하려면 rm(변수명)을 입력합니다.
> rm(dat)
3. 기술통계
summary() 함수를 이용하면 각 열 별 기술통계를 보여줍니다. 연속형 변수인 열은 6가지 기술통계(최솟값, 1 사분위수, 중앙값(2 사분위수), 평균, 3 사분위수, 최댓값)를 보여주고, 범주형 변수는 각 수준별 빈도수를 보여줍니다.
> summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100 setosa :50
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300 versicolor:50
Median :5.800 Median :3.000 Median :4.350 Median :1.300 virginica :50
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500iris 데이터의 Sepal.Length 열의 경우 class가 numeric 이므로 연속형, Species 열의 경우 factor이므로 범주형 입니다.
> class(iris$Sepal.Length)
[1] "numeric"
> class(iris$Species)
[1] "factor"1, 2, 3,...처럼 숫자로 된 범주형 변수인데 연속형 변수로 인식한다면 as.factor() 함수를 이용하여 범주형 변수로 변환할 수 있습니다. 예를 들어, dat 데이터의 5번째 열을 범주형으로 변환하려면 5열을 범주형으로 바꾸고 원래 데이터의 5열에 할당해야 합니다.
dat[,5] <- as.factor(dat[,5])
연속형 변수인 열에서 평균은 mean() 함수, 중앙값은 median() 함수, 분산은 var() 함수, 표준편차는 sd() 함수를 이용하여 구할 수 있습니다.
> mean(iris[,1]) #평균
[1] 5.843333
> median(iris[,1]) #중앙값
[1] 5.8
> var(iris[,1]) #분산
[1] 0.6856935
> sd(iris[,1]) #표준편차
[1] 0.8280661열의 개수가 여러 개인 데이터에서 각 열 별 평균을 한 번에 계산하고 싶다면 ColMeans() 함수를 사용합니다. 이때, 범주형인 열이 있는 경우 Error in colMeans(dat) : 'x' must be numeric 라고 에러가 뜨므로 범주형인 열은 제외해야 합니다.
> colMeans(iris[,1:4])
Sepal.Length Sepal.Width Petal.Length Petal.Width
5.843333 3.057333 3.758000 1.199333범주형 변수의 경우 table() 함수를 이용하면 summary() 함수의 결과와 마찬가지로 빈도표를 보여줍니다.
> table(iris[,5])
setosa versicolor virginica
50 50 50
4. Box plot(상자도표, 상자그림)과 해석
연속형 변수의 boxplot을 이용하여 데이터의 대략적인 분포를 확인할 수 있습니다. iris 데이터에서 연속형인 1~4열의 분포를 확인하기 위하여 boxplot() 함수를 이용해 상자도표를 그립니다.
> boxplot(iris[,1:4])
iris 데이터의 2번째 열인 Sepal.Width를 이용하여 boxplot을 그려 해석하겠습니다. 우선, 중앙에 가장 두꺼운 실선은 median(중앙값)을 나타냅니다. 회색 box의 위쪽 실선은 3rd quantile(Q3, 제 3 사분위수), 아래쪽 실선은 1st quantile(Q1, 제 1 사분위수)입니다. 따라서 회색 박스의 높이는 Q3 - Q1 인 IQR(Interquantile Range)가 됩니다. outlier(이상값, 이상치, 이상점)은 각각 Q1, Q3로부터 1.5 *IQR보다 더 멀리 떨어져 있는 점을 말하는데, boxplot에서 바깥쪽에 표시된 점들이 이상값을 나타냅니다. 회색 박스 부분을 제외하고 위, 아래에 있는 실선은 각각 (이상값을 제외한) maximum(최대값), minimum(최소값)을 나타냅니다.
따라서, Sepal.Width 데이터엔 이상값이 4개 있고 중앙값은 3 정도이며 IQR의 길이가 상대적으로 작은 것으로 보아 값들이 중앙값 근처에 모여있는 것으로 볼 수 있습니다.
> boxplot(iris[,2])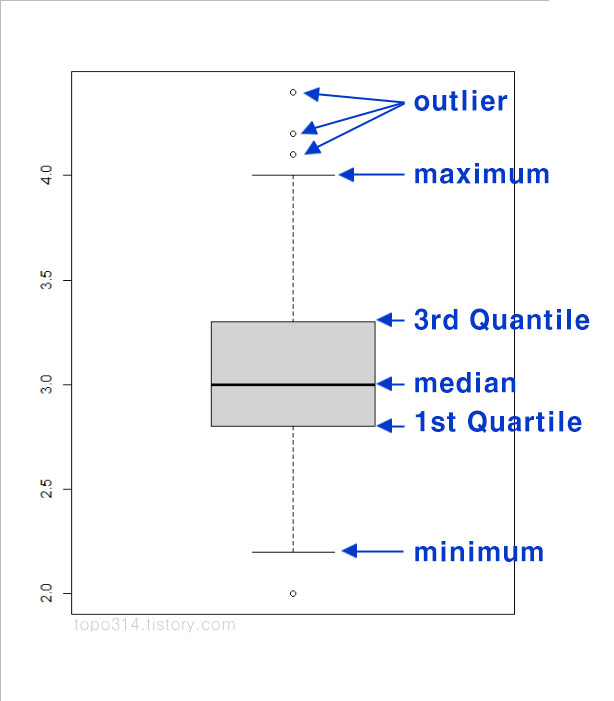
5. Histogram(히스토그램)
마찬가지로 히스토그램을 이용하여 연속형 변수의 대략적인 분포를 알 수 있습니다.
> hist(iris[,1], xlab = "Sepal.Length", main="Histogram of Sepal.Length")
'데이터분석 > R' 카테고리의 다른 글
| [R]가설검정과 예제로 보는 1집단 t-test, paired t-test, 2집단 t-test 결과 해석, t.test() in r (0) | 2021.10.31 |
|---|---|
| [R 기초]vector, list의 슬라이싱, 원소 추가, 수정, 제거 등 in r (0) | 2021.10.29 |
| [R 기초]print 관련 정리(print, paste, cat, sprintf 함수) in r (0) | 2021.10.23 |