1. Bagging(bootstrap aggregating)
1. 정의
2. 특징
3. Tree와 Bagging 비교
4. 단점
2. RandomForest(랜덤포레스트)
1. 정의
2. 특징
3. Bagging과 RandomForest 비교
3. Boosting(부스팅)
1. AdaBoost(Adaptive Boost)
2. Gradient Boosting
3. 특징
4. Gradient Boosting의 종류와 특징
-XGBoost
-LightGBM
-Catboost
4. Stacking
1. 정의
2. 특징
참고) [머신러닝]앙상블(Ensemble) 이론
https://topo314.tistory.com/80
[머신러닝]앙상블(Ensemble) 이론
1. 앙상블(Ensemble) 1. 정의 2. 특징 2. 앙상블(Ensemble) 종류 1. Bagging(배깅) 2. RandomForest(랜덤 포레스트) 3. Boosting(부스팅) 4. Stacking 1. 앙상블(Ensemble) 1. 정의 -앙상블 러닝(Ensemble learn..
topo314.tistory.com
1. Bagging(bootstrap aggregating)
-모델을 다양하게 만들기 위해 데이터를 재구성(행)
-Bootstrapping: 복원추출(중복 허용)
1. 정의
-n개의 데이터에 대해 n번 bootstrapping(복원추출)을 k번 반복하여 k개의 tree 적합
-이 k개의 tree로 test data에 대한 예측값을 계산하고 이 결과값의 평균으로 Y를 예측
-이때 각 단계마다 복원추출(중복 허용)로 인해 뽑히지 않은 데이터로 그 tree에 넣어 error율 계산
=> 계산된 k개의 error율의 평균=Out-of-Bag error(OOB error)
2. 특징
-장점: 학습데이터 내에서도 검증데이터에 대한 성능지표 계산 가능
-단점: 모형해석의 어려움으로 인해 실제에서 쓰기 어려움
-일반적으로 여러번 배깅할수록(k가 커질수록) 성능이 더 좋아지지만 시간이 오래걸리고 성능에 큰 차이x
=> 일반적으로 2~30번, 많으면 50번 배깅(그 이상은 성능 비슷)
-각 k개의 model의 mse가 높아도 data의 행별로 평균낸 mse는 낮아짐(앙상블의 개념)
=> 어떤 모델을 base로 쓰느냐에 따라 다르지만 성능 올라갈 확률이 높음
-test에 대한 다양한 의견 수렴을 위해 과적합 모델을 base로 사용(앙상블 특징)
3. Tree와 Bagging 비교
-깊이 성장한 트리: 과적합 심해짐, 편향 감소, 분산 증가
-bagging: 트리들의 편향을 유지하면서 분산 감소
-장점: 학습데이터의 noise에 강건해짐(=어떤 데이터가 들어와도 예측 잘함)(앙상블 특징)
-단점: 모형 해석의 어려움(앙상블 특징)
4. 단점
-bagging model은 여러 트리들의 결합이므로, bagging model의 분산은 각 트리의 분산+공분산
=> 복원추출이므로 각 tree가 독립이라고 보기 어려워 공분산 Cov(X,Y)이 0이 되기 어려움(비슷한 모델 생성)
=> Tree가 증가하면 모델 전체의 분산이 증가할 수도
=> 각 tree의 공분산을 줄여야함
2. RandomForest(랜덤포레스트)
-모델을 다양하게 만들기 위해 데이터와 변수를 재구성(행, 열)
-데이터, 변수를 random하게 뽑아서 다양한 모델 생성
-목적: 조금 더 다양한 모델 만들기, base learner간의 공분산 줄이기(bagging의 단점 완화)
1. 정의
-변수 랜덤 선택을 제외하곤 bagging과 동일
-n개의 데이터에 대해 n번 복원추출하고 변수를 랜덤하게 선택하는 과정을 k번 반복하여 k개의 tree 적합
-랜덤하게 뽑을 변수의 수는 hyper parameter(사용자 지정)
=> 일반적으로 sqrt(p)개, p개(bagging)보다 적게 사용
-이 k개의 tree로 test data에 대한 예측값을 계산하고 이 결과값의 평균으로 Y를 예측
-이때 각 단계마다 복원추출(중복 허용)로 인해 뽑히지 않은 데이터로 그 tree에 넣어 error율 계산
=> 계산된 k개의 error율의 평균=Out-of-Bag error(OOB error)
2. 특징
-모델의 분산을 줄여 일반적으로 bagging보다 성능이 좋음
3. Bagging과 RandomForest 비교
-RandomForest의 전체 모델 분산이 더 작으므로 bagging보다 성능이 더 좋음
| Bagging | RandomForest | |
| 변수 개수 | p개 모두 사용 | p보다 적게(랜덤 선택) |
| 각 모델간 공분산 | 상대적으로 더 큼 | 상대적으로 더 작음 |
| 전체 모델 분산 | 상대적으로 더 큼 | 상대적으로 더 작음 |
코드, hyper paremeter 참고) sklearn.ensemble.RandomForestClassifier
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
sklearn.ensemble.RandomForestClassifier
Examples using sklearn.ensemble.RandomForestClassifier: Release Highlights for scikit-learn 0.24 Release Highlights for scikit-learn 0.24, Release Highlights for scikit-learn 0.22 Release Highlight...
scikit-learn.org
3. Boosting(부스팅)
-오분류된 데이터에 대해 좀 더 가중치를 두어 학습(잘 맞추기 어려운데이터를 집중적으로 학습)
-부스팅 기법들 간 차이는 오분류된 데이터를 다음 round에서 어떻게 반영할 것인가의 차이
-초기에는 모든 데이터의 가중치 동일, 각 round가 종료된 후에 가중치, 중요도 계산
1. AdaBoost(Adaptive Boost)
-기본 부스팅 방법
-오분류된 데이터들에 더 큰 가중치를 주어 다음 round 샘플링에 반영
-첫 시행에서 모든 데이터에 대해 동일한 가중치를 주어 적합한 뒤, 오분류된 데이터의 샘플링될 확률에 가중치를 주어 다음 round로
=> 이 과정(round)을 설정 횟수만큼 반복
-각 round에서 학습된 base learner에 가중치를 두어 strong learner를 적합
-최종 의사결정 방법:
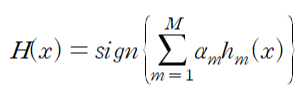
-H(x): 최종 분류기(final classifier)
-h_m (x): m round에서 생성된 약한 분류기(weak classifier)
-alpha_m: m번째 round에서 계산된 정확도(각 분류기의 정확도에 따라 가중치를 줌)
=> alpha_m이 크면(m번째 round의 정확도가 높으면), 분류기 m이 좋은 성능을 보임(오차율 낮음)
=> alpha_m이 작으면(m번째 round의 정확도가 낮으면), 분류기 m이 안좋은 성능을 보임(오차율 높음)
2. Gradient Boosting
-요즘 가장 많이 쓰임
-이전 round의 합성 분류기(strong learner)에 데이터별 오차를 예측하는 새로운 약한 분류기를 학습
-잔차를 최소화시키면서 학습
=>gradient(: Loss 함수의 기울기)의 negative를 최소화시키면서 학습
-과정 수식:

-각 단계마다 Y가 아닌 이전 단계의 잔차(오차, residual)를 예측하는 model을 적합
=> 단계를 거칠수록 오차가 작아져 Y를 더 잘 예측함(small error -> 0 in 학습 데이터)
-H_0(첫번째 weak learner)만 Y를 예측하고, 나머지는 이전 단계의 오차를 예측
3. 특징
-복원추출시 가중치 분포를 고려
-오분류된 데이터가 가중치를 더 얻게 됨에 따라 다음 round에서 더 많이 고려
-단점: 시간이 오래 걸림
4. Gradient Boosting의 종류와 특징
-각 방법의 자세한 개념보다 라이브러리를 설치, 활용하는 것이 중요
-일반적으로 성능, 속도 면에서 Xgboost보다 Catboost와 LightGBM가 더 좋음
=> Catboost, LightGBM > Xgboost
-XGBoost
-캐글 대회에서 많이 활용
-학습을 위한 목적식(loss function)에 regularization term이 추가되어 모델이 과적합되는 것을 방지
-복잡한 모델이지만, Gradient Boosting에 비해 조금 더 심플해짐(과적합 방지)
-LightGBM
-leaf-wise loss사용(뿌리를 더 깊게 내려서 training loss를 줄일 수 있음)
-장점: Xgboost보다 속도가 빠름, GPU 지원
-과적합에 민감하므로 대량의 학습데이터 필요
-주로 많이 사용(Catboost보다 자료 많음)
-Catboost(unbiased boosting with categorical features)
-분산을 최소화하면서 bias를 피하는 boosting 기법
-categorical feature가 많을 때 잘 맞음(one-hot encoding이 아닌 수치형으로 변환)
-학습데이터에 대해 샘플링이 안된 데이터의 잔차를 추정하여 학습시킴
4. Stacking
-모델의 output값을 새로운 독립변수로 사용
-앙상블의 한 개념(라이브러리x, 직접 코딩해야함)
1. 정의
-Meta learner, 다양한 모델을 결합하여 사용하는 기법
-학습 데이터로 여러 모델을 결합하여 적합한 후, 다시 학습데이터로 계산한 예측값을 독립변수(X)로 사용
=> 이 데이터로 단일 모델(learner)을 이용하여 적합한 후, 검증데이터로 계산한 예측값을 최종 결과(Y)로 사용
-학습 데이터와 검증 데이터 모두 5or10 cross validation하여 사용
-새로운 학습데이터=기존 학습데이터 + 각 모델별 예측값 (검증데이터도 마찬가지)
=> 단일 모델을 새로운 학습데이터로 적합하고, 새로운 검증데이터로 예측
2. 특징
-성능이 조금 더 좋아지지만 학습시간이 오래걸려서 비효율적임(캐글 대회 등을 제외하곤 잘 안씀)
-목표: 다양한 예측값을 만드는 것
-기존 feature를 사용하지 않고 각 모델별 prediction값만 사용하기도 함
=> 이경우 단일모델로 regression(logistic, 다중선형회귀)을 많이 사용
'데이터분석 > 이론' 카테고리의 다른 글
| [머신러닝]군집분석(Clustering) - K-means clustering, Hierarchical clustering, DBSCAN 이론 (0) | 2022.03.15 |
|---|---|
| [머신러닝]중요 변수 추출 방법 - feature importance, shap value 이론 (0) | 2022.03.15 |
| [머신러닝]앙상블(Ensemble) 이론 (0) | 2022.03.13 |
| [머신러닝]의사결정나무(Decision Tree) 이론 (0) | 2022.03.13 |
| [머신러닝] SVM(Support Vector Machine) 이론 (0) | 2022.03.12 |


