1. 군집분석(Clustering)이란
1. 정의
2. 특징
3. 종류
2. K-means clustering
1. 정의
2. 점과 점 사이의 거리 측정
3. 특징
4. k를 설정하는 방법
-Elbow method
-Silhouette method
5. k-medoids clustering
3. Hierarchical clustering(계층적 군집분석)
1. 정의
2. 특징
3. cluster간 거리 종류
4. DBSCAN
1. 정의
2. 특징
3. hyper parameter 설정
1. 군집분석(Clustering)이란
1. 정의
-비지도학습(unsupervised learning)의 한 종류(Y가 없음)
-각 데이터의 유사성을 측정하여 유사도가 높은 집단끼리 분류하고, 군집 간 상이성을 규명하는 방법(거리 기반)
-목적: 데이터 분류, 그룹간 특성 파악
-ex. 고객 segmentation(분류)을 통한 마케팅 활용 방안, 군집 별 추가 분석 수행
2. 특징
-일반적으로 정확도가 낮음(classification과 다름)
-대부분 지도학습이므로, 잘 사용하지 않음(사회과학적 해석, 현상분석시 사용)
3. 종류
-K-means clustering: 데이터를 사용자가 지정한 k개의 군집으로 나눔
-Hierarchical clustering(계층적 군집분석): 나무 모양의 계층 구조를 형성해나가는 방법
-DBSCAN: k개를 설정할 필요 없이 군집화 할 수 있는 방법(최근 강조됨)
2. K-means clustering
1. 정의
-각 군집에 할당된 포인트들의 평균 좌표를 이용해 중심점을 반복적으로 업데이트
-과정:
1) 초기 중심점(포인트)는 랜덤하게 찍음
2) 각 중심점에 대해 가까이 있는 데이터들끼리 군집으로 나눔
3) 현재 할당된 군집의 중심점을 찾아서 업데이트(중심점: 군집 내부 점들의 좌표의 평균)
4) 업데이트된 중심점을 기준으로 다시 가까이 있는 데이터들끼리 군집 할당
5) 이 과정을 반복하여 데이터 할당이 바뀌지 않으면 멈춤(각 군집의 할당이 바뀌지 않을 때까지 반복)
2. 점과 점 사이의 거리 측정
-맨해튼 거리(Manhattan distance): 택시거리, x축&y축과 평행하게 가는 거리
-수식:

-유클리드 거리(Euclidian distance): 대각선으로 가로지르는 거리
-수식:
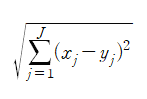
3. 특징
-단점:
-k를 사용자가 설정해야됨(k 설정이 어려움, hyper paremeter에 따라 성능 달라짐)
-초기 중심값에 민감(초기 포인트에 따라 군집이 다르게 형성될수도)
-noise와 outlier에 민감
-원형 군집이 아닌 경우 군집화를 이루기 어려움(섞인 데이터 등)
-데이터의 차원이 커지면(변수가 많아지면) 거리가 무의미해짐
-잘 안쓰임
-4차원 이상이면 시각적으로 확인이 불가능하기때문에 잘 군집화되었는지 판단이 힘듦
-최적의 k를 설정하고, 각 군집에 대해 해석하고, 결과를 생각해보는 것이 중요
4. k를 설정하는 방법
-가장 좋은 방법: 사전에 알고있는 군집의 개수를 k로 설정(알기 힘듦)
-거리를 기반으로 하므로, 데이터의 차원이 커질수록 Elbow method, Silhouette method를 써도 잘 안맞을 확률 높음
-Elbow method
-더 많이 사용, 직관적
-군집 간 분산(BSS)와 전체 분산(TSS)의 비율로 판단, (WSS: 군집 내 분산)

=>BSS가 커질수록(WSS가 작을수록) 좋음
-k가 커질수록 BSS도 커짐(k가 데이터 수이면 ratio=1)
-비율의 한계비용(marginal cost)이 줄어드는 지점(비율의 증가폭이 작아질 때)이 최적의 클러스터 개수(k)
-Silhouette method
-실루엣 s(i) 수식: 1에 가까울수록 객체 i가 올바른 군집에 분류된 것(클수록 좋음)

-a(i): 객체 i와 그 객체가 속한 군집의 데이터들과의 거리(비유사성)
-b(i): 객체 i가 속하지 않은 다른 군집의 모든 데이터들과의 거리의 최소값(가장 가까운 군집)
5. k-medoids clustering
-k-means clustering의 단점을 약간 보완한 방법
-군집의 무게중심을 구하기 위해 평균 대신 중간점(medoids, 중앙 데이터)를 중심점으로 사용
-k-means보다 조금 더 좋음 성능을 보임(특히 이상치가 있을 때)
-단점: (k-means와 마찬가지로)원형 군집이 아닌 경우 군집화를 이루기 어려움, hyper paremeter에 따라 성능 달라짐
| K-means | K-medoids | |
| 중심 | 군집의 평균 값 | 군집의 중간점 |
| 이상치 | 민감 | 덜 민감 |
| 계산 시간 | 상대적으로 적게 걸림 | 상대적으로 오래 걸림 |
| 파라미터 | 군집 개수 k, 초기 중심점 | |
| 군집 모양 | 원형 군집이 아닌 경우 군집화 어려움(단점) | |
3. Hierarchical clustering(계층적 군집분석)
-개체들을 가까운 집단부터 순차적/계층적으로 차근차근 묶어 나가는 방식
1. 정의
-과정:
1) 모든 개체들 사이의 거리를 계산하는 유사도 행렬 계산
2) 거리가 인접한 관측치끼리 묶어서 cluster 형성
3) cluster를 반영하여 유사도 행렬 update후 인접 관측치끼리 묶어서 새로운 상위 cluster 생성
4) 위 과정 반복

2. 특징
-decision tree와 비슷하게 dendogram으로 클러스터링 결과 시각화 가능
=>눈으로 보기 쉬움, 크게/세세하게 확인 가능
-아래에서부터 생성하지만 해석은 위에서부터 가능(역으로 해석 가능)
-사전에 군집의 개수를 정하지 않아도 수행 가능
-직관적, 이해하기 쉬운 알고리즘
3. cluster간 거리 종류
1. 최소거리(Min, Single Link): 군집간 점들의 최소거리
2. 최대거리(Max, Complete Link): 군집간 점들의 최대거리
3. 평균거리(Average Link): 군집간 점들의 거리의 평균
4. Centroids: 군집의 중앙점끼리의 거리
5. Ward distance: 두개의 클러스터가 병합되었을 때 증가되는 변동성(중심점과 모든 데이터간의 거리의 제곱)의 양
4. DBSCAN
-Density-based Spatial Clustering of Applications with Noise
1. 정의
-과정:
1) eps, minPoints 설정
2) 랜덤하게 점을 선택한 후 eps 반경 내에 있는 데이터를 하나의 군집으로 설정
3) 군집에 추가된 점에 대해 eps 반경 내에 있는 데이터를 하나의 군집으로 설정
4) 3의 과정을 반복하면서 군집이 점점 커짐
=> 군집 밖에 있는 데이터는 outlier(noise) or 다른 군집에 속함
-hyper parameter: eps-neighbors(epsilon-neighbors), MinPts(min points)
1) eps-neighbors: 하나의 데이터를 중심으로 epsilon 거리 내에 있는 데이터들을 하나의 군집으로 구성(데이터 반경)
2) MinPts: 반경 안에 들어올 수 있는 데이터의 수
2. 특징
-density-based clustering중 가장 유명, 성능 우수(k-means보다 먼저 사용)
-직관적이고 간단한 알고리즘
-장점:
1) k-means와 달리 군집의 수 설정할 필요 없음(cluster의 수를 설정하지 않아도 알아서 분류함)
2) 노이즈 개념으로 인해 이상치 탐지 가능
3) 다양한 모양의 군집이 형성될 수 있으며 군집끼리 겹치지 않음
4) hyper parameter가 적고(2개), 적용 분야에 대한 사전 지식이 있는 경우 비교적 쉽게 설정 가능
-단점:
1) eps의 크기에 따라 성능이 크게 좌우됨
2) 군집끼리 겹치지 않으므로(한 데이터당 하나의 군집) 시작점에 따라 다른 모양의 군집 형성
3) 군집별로 밀도가 다른 경우에 사용시 군집화가 제대로 이루어지지 않음
3. hyper parameter 설정
-기본값으로 설정 후 바꿔보면서 찾기
-군집분석을 적용할 데이터에 대한 이해도가 충분하면 설정이 쉬움
-1. MinPts의 설정
-일반적으로 minPts=변수의 수+1, minPts>=3
-minPts=1이면 데이터 하나하나가 개별적인 군집으로 형성됨
-2. Eps의 설정
-가장 민감한 parameter(너무 커도, 너무 작아도 안됨)
-너무 작으면 하나의 군집으로 묶이지 않아 각각의 군집으로 형성됨(k-means에서 k=n인 경우와 비슷)
-너무 크면 모든 데이터가 하나의 군집으로 형성
-일반적으로 KNN(K-nearest neighbor) graph의 distance를 그래프로 나타낸 후, 거리가 급격하게 증가하는 지점으로 설정
-여러 값으로 바꿔보면서 찾기
'데이터분석 > 이론' 카테고리의 다른 글
| [머신러닝]중요 변수 추출 방법 - feature importance, shap value 이론 (0) | 2022.03.15 |
|---|---|
| [머신러닝]앙상블(Ensemble) - Bagging, RandomForest, Boosting, Stacking 이론 (0) | 2022.03.13 |
| [머신러닝]앙상블(Ensemble) 이론 (0) | 2022.03.13 |
| [머신러닝]의사결정나무(Decision Tree) 이론 (0) | 2022.03.13 |
| [머신러닝] SVM(Support Vector Machine) 이론 (0) | 2022.03.12 |


